Tutorial: Generate GRM Only¶
This example will show you how to generate the GRM step only. It will guide you through how to properly set the logic, remind you to set the environment, list all the additional files you need, and finally which user parameters need to be set.
Section: Logic and Overview¶
GRM only means you want to run the GRM step. This is analagous to setting the pipeline logic kewords to the following:
Note, SkipChunking can be set to either true or false because it is only used if GenerateAssociation is set to true.
GenerateGRM:true
GenerateNull:false
GenerateAssociations:false
GenerateResults:false
SkipChunking:false
If the pipeline is set to the above logic, the following workflow will be executed:

Section: Step-by-Step Tutorial¶
STEP 1: Set the logic¶
As stated about above, open your config file (.txt) and make sure the logic is set to the following:
GenerateGRM:true
GenerateNull:false
GenerateAssociations:false
GenerateResults:false
SkipChunking:false
STEP 2: Set the environment¶
Open your config file (.txt) and make sure you set the path to where the bind point, temp bind point, and container image are located. I suggest you set the BindPoint keyword to the same path as where the container is located to avoid any confusion. If you have a tmp directory you want to use as scratch space, set that path as well. If this doesn’t exist or you choose not to use it, set the keyword BindPointTemp to be the same as the path listed in the keyword BindPoint.
BindPoint:/path/to/bind/container
BindPointTemp:/path/to/tmp/
Container:/path/to/saige-brush-v039.sif
STEP 3: Ensure you have all the files required¶
For running the GRM only, you will need access to the following files:
- LD-pruned plink file
used for when logic parameters
GenerateGRMis set to true and/orGenerateNullis set to true.fulfills parameter
Plinksee Parameter: Plink for formatting
STEP 4: Set the path and values to all the required input parameters¶
Now that you have all the required files, it is time to set the values and locations within your config file using the keywords expected. Here are the required keywords and how to specify them:
This
RUNTYPEparameter need to just be here for placeholder purposes, however it is required. It has no impact on the pipeline, except as a header to check that it exists.RUNTYPE:FULL
The next set of parameters are the keywords that relate to file inputs:
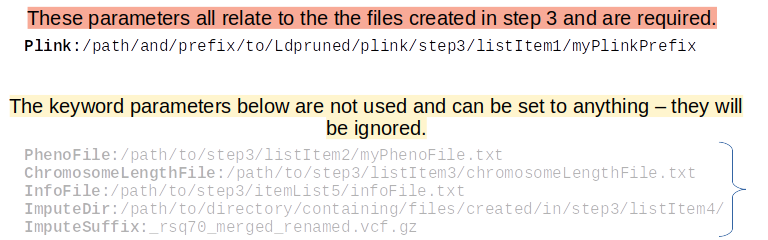
Here are some required general keyword parameters that need to be set:

The following two sets of keyword parameters affect the GRM step, i.e.
GenerateGRM:true:
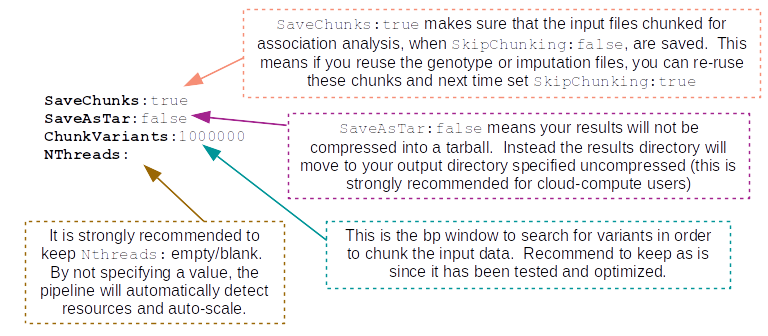
These parameters I recommend to keep as is, unless you are familiar with the pipeline and have a reason to change them:
STEP 5: Running the pipeline¶
To run the pipeline make sure the files are all accessible to the container relative to the bindpoint.
Once all the files are accessible and the config is ready, the following command will run the pipeline. For those running this through a job-scheduler such as SLURM, LSF, PBS, etc… the log and error files will output to the scheduler keyworkds for log and error so please set those in your job submission. Then you can put the following line in your batch script to run the pipeline:
$ ./saigeBrush myConfigFile.txt
For those running this ** without a job-scheduler** the log and error files will output/print to your screen/standard out. Therefore, please specify log and error files by running the pipeline as follows:
$ ./saigeBrush myConfigFile.txt 1> myLogName.log 2> myLogName.err
Section: Generated Output¶
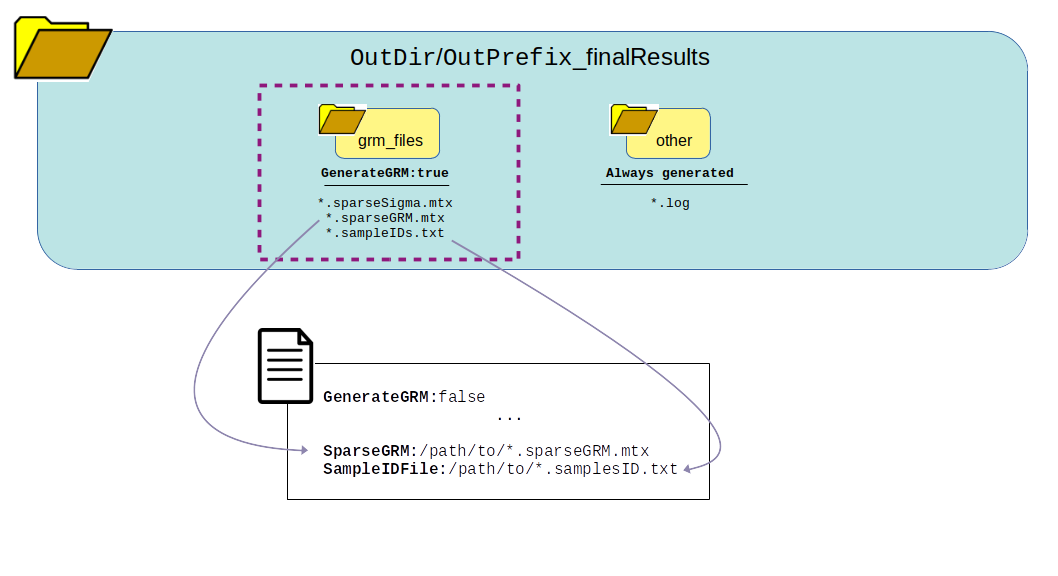
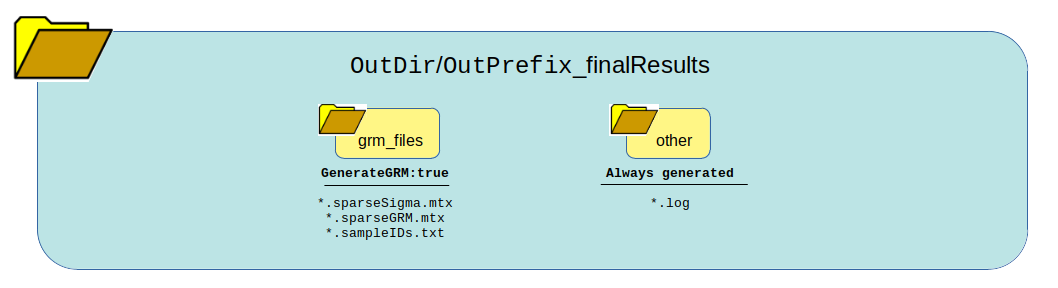
The following graphic shows how all the data generated from running the logic of this pipeline will be organized and which files are present. One thing to notice is the list of files generated in each directory based on whether the pipeline logic is set to true or false. Many of these outputs and be re-used under certain circumstances to save time and bypass running certain steps of the pipeline in the next run.
Warning
IMPORTANT PLEASE READ! Although the pipeline tries its best to not generate output as critical errors occur, this is not always the case. It is particularly important to parse through the standard error output, as well as the log file produced in the other directory of your output directory. The log file can be quite large, therefore, it is recommended to use grep to seach for keywords. I would recommend the following: grep -i "err" other/*.log, grep -i "warn" other/*.log, and grep -i "exit" other/.*log. Also, please see the note below, for additional ways to parse the log file.
See also
For a interpreting and searching the log files for potential pipeline errors, see Parsing Through StdErr and StdOut.
Once it is confirmed that the error and log files ran successfully without major errors, the results and files are ready for viewing. The directory of highest interest will be the grm_files directory.
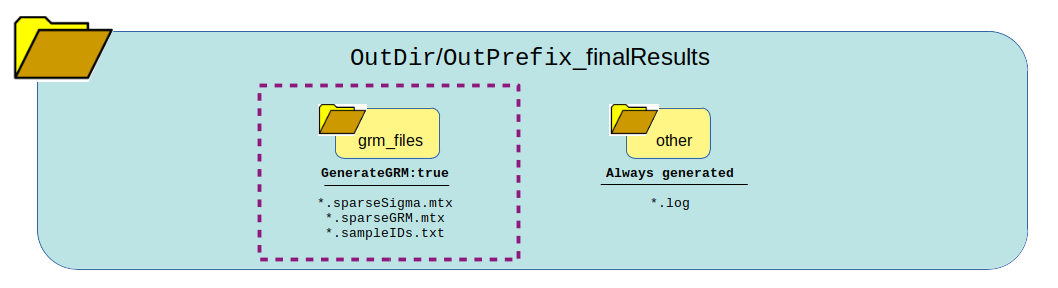
These files can be opened in R. The .mtx files are just sparse matrix files. The *.sampleIDs.txt file is important to keep and not mutate! This is the order of the samples in the sparse matrix. Therefore, do not shuffle or mutate this file and make sure to keep it together with the .mtx files.
Section: Re-Use Next Steps¶
The output generated here can now be used as input file parameters in the config file for another run that requires the GRM input. If you use these files for another run you can now set the logic parameter GenerateGRM: to false since you no longer need to calculate the GRM and are going to reuse the GRM that was just calculated by setting the following parameters: